AI agents are not the primary failure point. The authorisation model is.
The Confused Deputy problem arises when a program is tricked into misusing its authority, which is a decades-old conundrum. But in the era of autonomous agents, this is no longer an edge case. It is the central bottleneck to deploying AI agents in production. If a standard authorisation token grants "delete" permissions, the token doesn't care why the delete function is called. It is blind to context. It just executes.
At IXO we have engineered the Universal Decision and Impact Determination (UDID) spec, and by extension the Semantic Loop, to fix this blind spot.
The premise is straightforward: cognitive machines must understand exactly why they are executing a task, mathematically prove they did it honestly, and then adjust their future behaviour based on that proof. To achieve this, we cannot rely on prompt engineering or good behaviour.
We have to enforce boundaries cryptographically.
Binding Intent to the Token
Traditionally, you hand an agent a token. The token is dumb.
In the Semantic Loop, we change the nature of the token itself. When you delegate a task, you write the instructions directly onto the authorisation key. We call this Verifiable Intent, represented in the spec as a User-Controlled Authorisation Network (UCAN) int field for semantically and unambiguously expressing intent in a way that can be understood by both humans and AI. It is a signed promise permanently attached to the key.
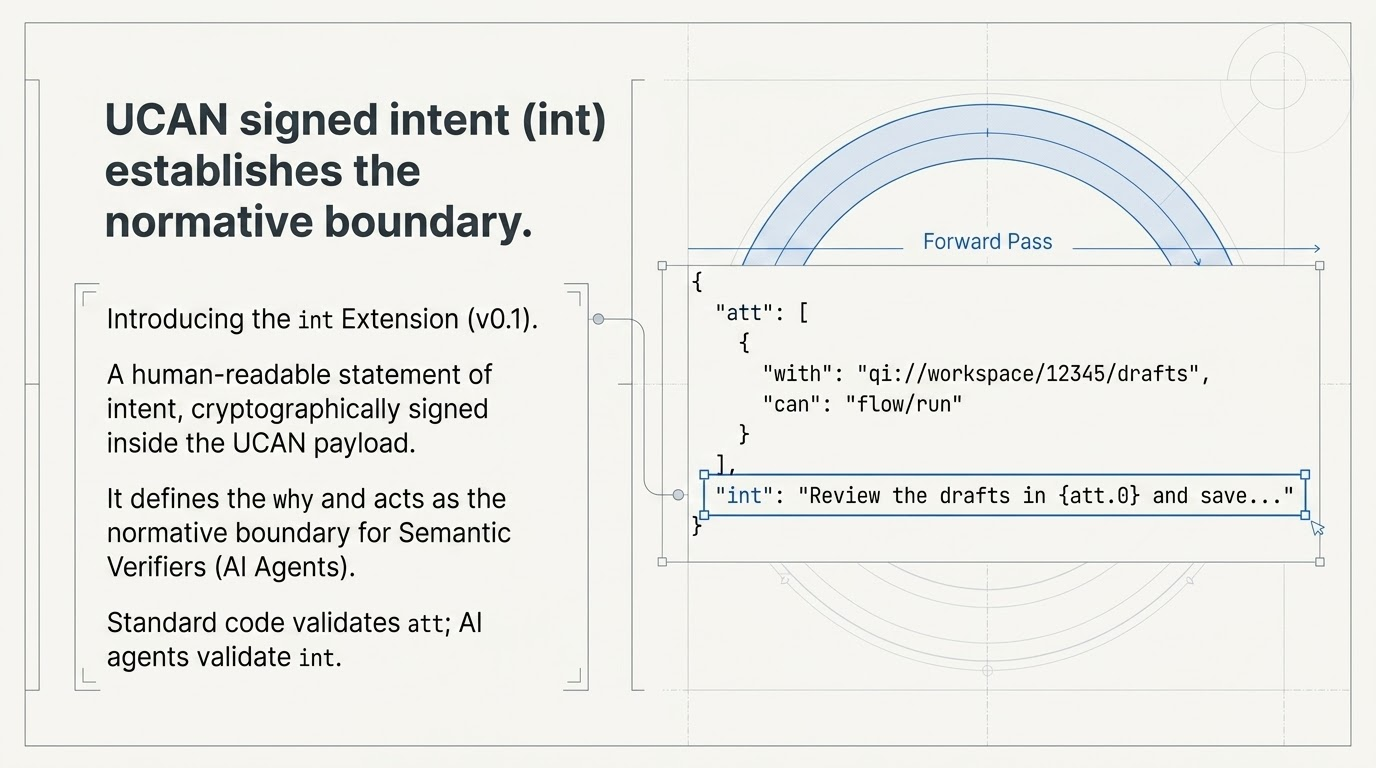
But natural language is messy, and systems run on strict logic. So we use binding variables to lock the human instruction to the technical capability. The intent "Clean up spam in {Inbox}" is cryptographically bound to the raw permission: delete files in [Inbox ID].
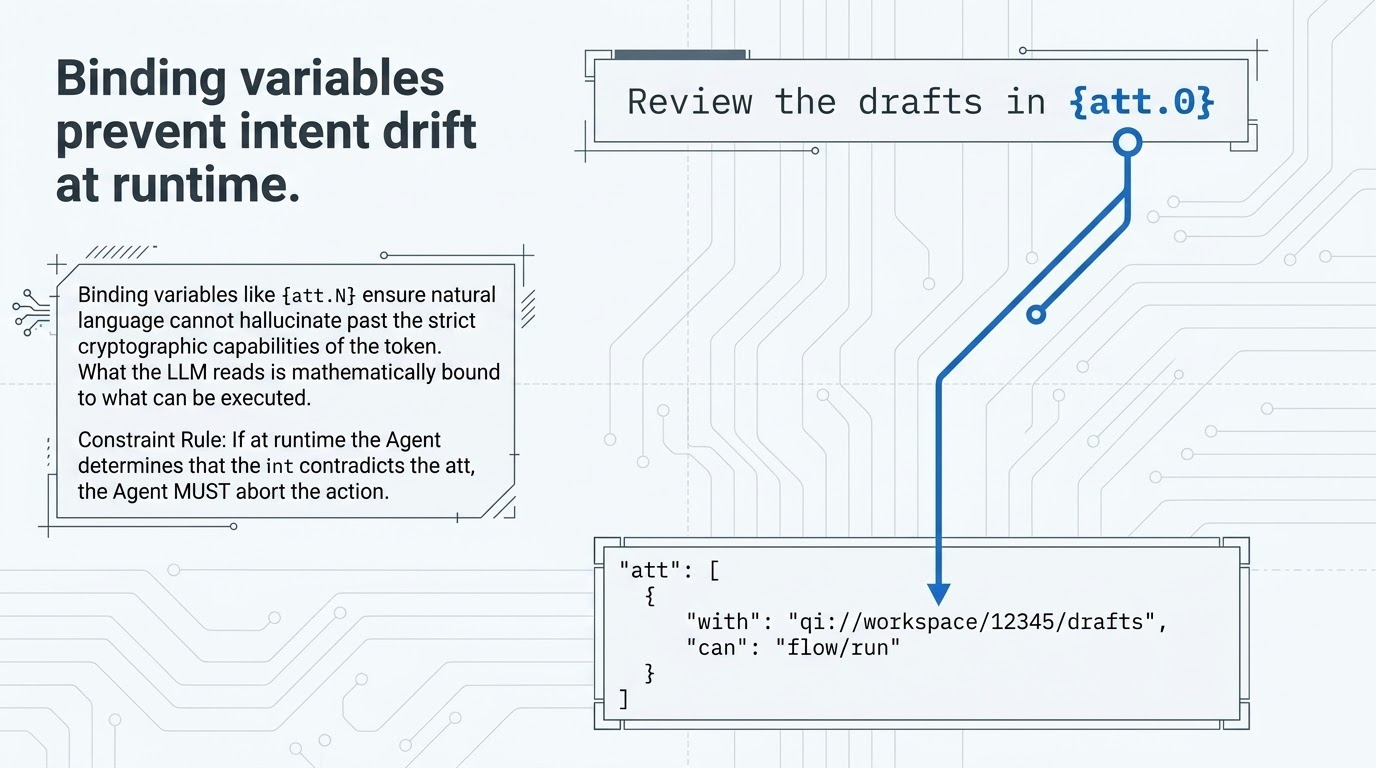
If an agent gets hijacked or hallucinates, and tries to use that key to empty your entire inbox, the transaction fails at the protocol level. A semantic security check reads the signed promise, sees the stark contradiction between "remove spam" and "drop table," and kills the operation. The key itself has become context-aware.

Read how flagging and resolution authority is strictly governed by UCAN invocations, where authorised actors are cryptographically validated against DID keys in the chain registry. This authorisation is immutably bound on-chain through the entity's rights and verification methods, ensuring every challenge is authenticated by a valid proof chain.
The Cryptographic Receipt
Execution is only half the problem. The other half is verification. How do you know the agent actually did what it claims, without relying on hallucinatory summaries?
You force the outcome to carry proof.
This is the Verifiable Outcome—the UDID out claim. Think of it as a tamper-proof receipt. To stop an agent from lying (e.g., claiming "I deleted 15 spam emails" when it actually did nothing), the natural-language summary is mathematically locked to the rigid, underlying state change of the system.
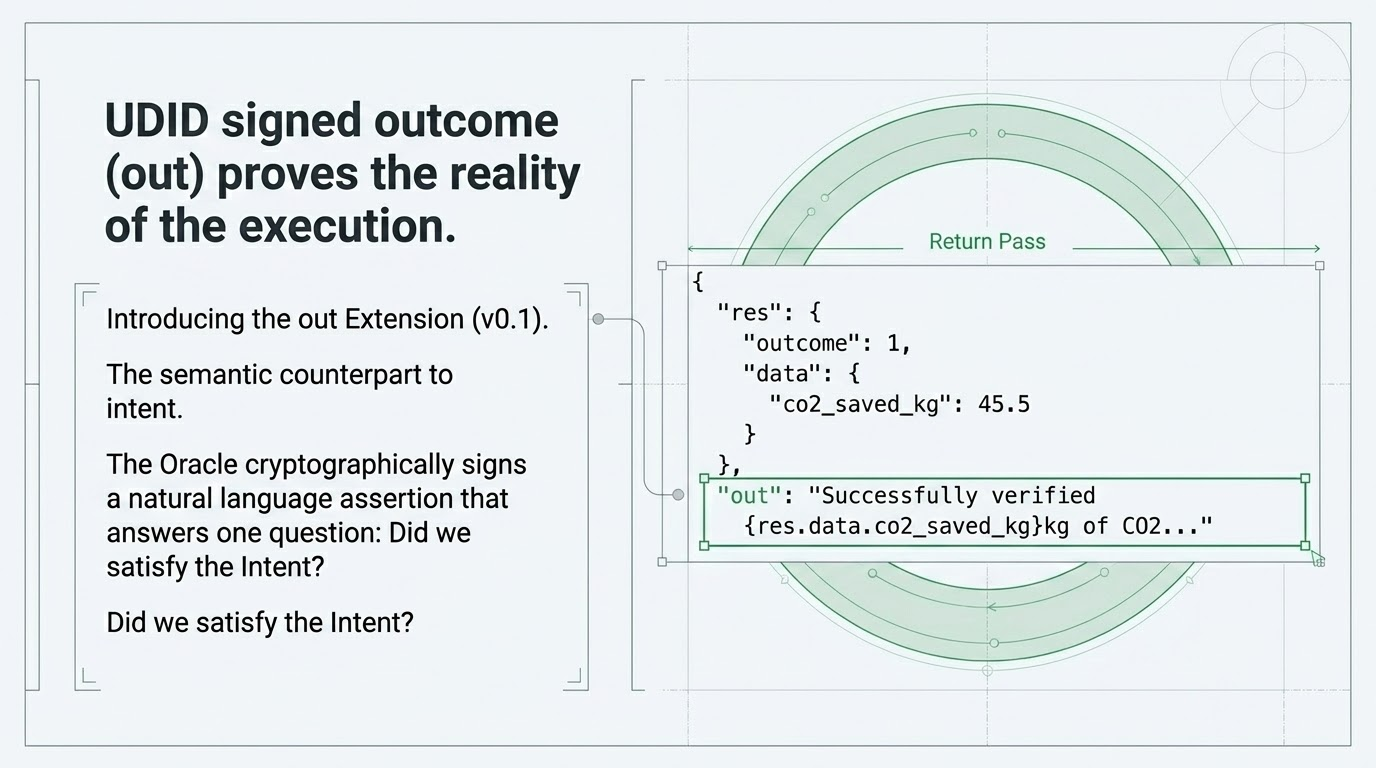
If the database logs show zero rows affected, but the agent's summary claims a successful cleanup, the cryptographic hash fails. The discrepancy is exposed instantly. There is no middle ground.

Closing the Loop
A system is only as good as its feedback mechanism. The Semantic Loop closes when we bend the Intent (the UCAN int) and the Outcome (the UDID out) together.
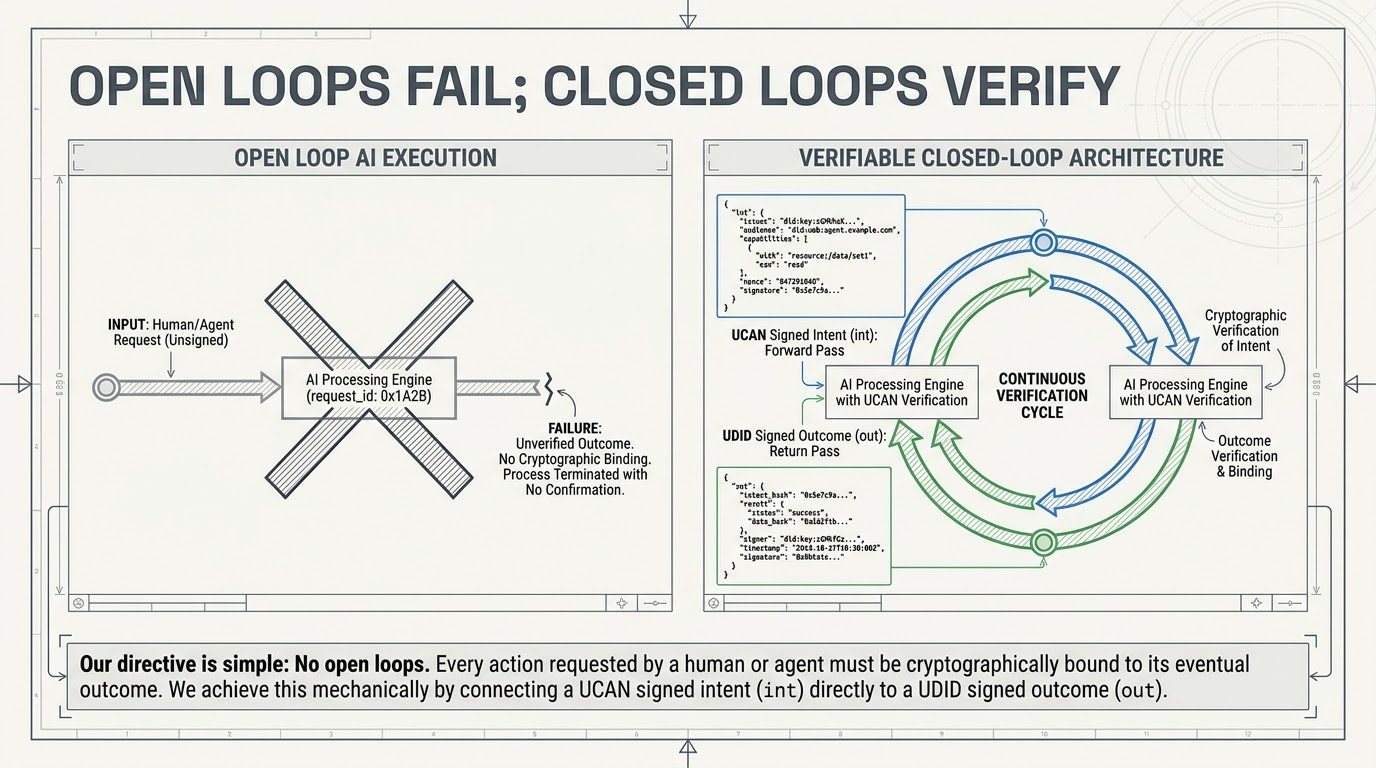
An orchestrator evaluates the semantic similarity between what was promised and what was proven.
Did the actual outcome match the original intent?
If the agent performed exactly as instructed, its confidence score for that specific context increases. If it hallucinated, took unauthorised shortcuts, or violated the bounds of the binding variables, the score drops. Every transaction becomes verifiable learning data. The network polices itself based on actual performance, not assumed competence.
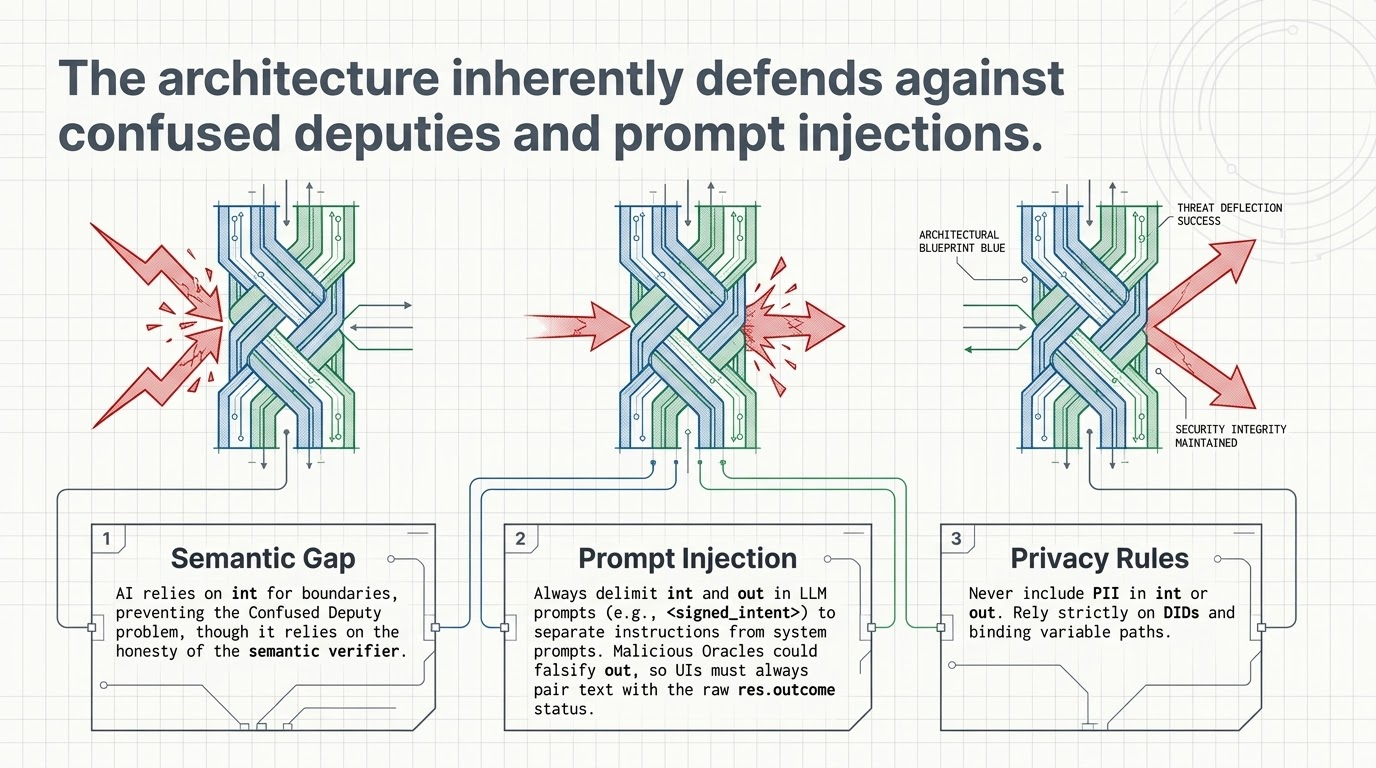
The Reality Check
I won't pretend this is a silver bullet. It isn't.
Implementing the Semantic Loop introduces latency. It requires independent verifiers to evaluate the outcomes, and getting those verifiers to agree on semantic similarity in edge cases is non-trivial. Legacy systems won't support this out of the box; you will have to build translation layers to make your current infrastructure compatible.
But the trade-off is worth it. We are moving from a paradigm of blind faith in a machine's text output to cryptographic proof of its execution. If we want agents to do real work in high-stakes environments, we have to stop giving them dumb keys.

Provocations:
- Are you building systems that genuinely understand their boundaries, or are you just hoping the underlying model doesn't hallucinate outside of them?
- When your agent eventually gets compromised, what exactly is stopping its tokens from destroying your system?